Knowledge Base
Narrative Snowflake Native App Data Flows
Narrative Snowflake Native App Data Flows
The Narrative Snowflake Native App integrates Snowflake with Narrative's platform, facilitating seamless data interaction and management directly within Snowflake's native environment. This article provides a deeper dive into the data flows between a customer's Snowflake account, the Narrative platform, and Connector Framework egress destinations.
Data Plane vs Control Plane Separation
Narrative Control Plane
- Managed by Narrative.
- Hosts metadata, user permissions, and configurations.
- Contains operational data like NQL query definitions, job statuses and logs.
Customer Data Planes
- Managed by the customer (e.g., Snowflake account).
- Hosts sensitive customer datasets.
- Contains the raw and processed data utilized in data queries and deliveries.
- Hosts the execution engine for all queries run by Narrative in the data plane (processing occurs in the customer's Snowflake account)
- All processing and storage costs for operating the Snowflake Native App occur in a customer's Snowflake account and will be billed by Snowflake as normal.
Data Flow
Data Integration
- Connecting Snowflake to Narrative:
- Users connect their Snowflake account to Narrative by installing the Narrative Snowflake Native App and providing their Narrative API Key.
- This registers a new Data Plane in the Narrative platform that represents the customer's Snowflake account and region.
- Registering Snowflake Tables:
- Snowflake tables are registered as datasets within the Narrative platform.
- Datasets contain metadata only, limited to the schema of a Snowflake table, additional metadata such as names and descriptions, and optionally sample data and dataset statistics.
- Queries are executed within the Snowflake account, ensuring security and data privacy.
Data Management
- Queries created in the Narrative platform are translated to Snowflake SQL.
- These queries are executed in your Snowflake instance.
- Results are processed within Snowflake (generating new tables in your Snowflake account where necessary) without moving data externally.
Data Delivery
- Processed data can be delivered to various endpoints (e.g., The TradeDesk, Facebook) when a Connection is created between a dataset and an Egress Connector Destination.
- Data flows from Snowflake through the Narrative Connector Framework to the targeted destinations.
- Note: In Alpha, this data makes a stop on Narrative's infrastructure before being cached and delivered to connector destination endpoints. In future versions of Narrative's Snowflake app, data will flow directly to connector destinations.
Snowflake Table Metadata to Control Plane
When integrating Snowflake with the Narrative platform, certain metadata may be shared with the Narrative Control Plane to optimize data management and operations. Here are the key types of metadata that may be shared:
- Data Schema:* Field Names: Names of the columns in the table.
- Field Types: Data types of each field (e.g., INTEGER, STRING).
- Sample Data (Optional):* A sample of 1000 rows can be automatically shared.
- This is optional and requires user opt-in by clicking "Send Sample Data" during or after configuration.
- Users can alternatively call the Sample API directly with cleansed data or forgo sending sample data.
- Dataset Statistics (Optional):* Column Count: Total number of columns in the table.
- Unique Values: Count of unique values for each column.
- Table Size: Size of the table in rows and bytes.
- This requires user opt-in by clicking an appropriate button similar to sample data sharing.
- Log Files (Optional):Operational Metadata: Includes job statuses, execution times, and other operational information.Note on Logs:brPlease note that logs generated and managed by the Narrative platform contain only metadata and operational information, such as job statuses and execution times. These logs do not include any rows of actual data from your datasets, ensuring the privacy and security of your data.
Snowflake Containerized Services (Private Preview)
This workflow leverages Snowflake’s Snowpark Container Services, enabling Narrative’s Snowflake Native App to execute AI models and other software functionalities directly within a customer’s Snowflake environment. By using Snowpark Container Services, Narrative can facilitate data mapping, normalization, and enrichment without transferring data out of the customer’s Snowflake instance, ensuring data remains secure and private. This containerized processing is fully opt-in, giving customers complete control over the data shared with Narrative.
Learn more about Snowflake's Snowpark Container Services.
Overview: Data Mapping Suggestion Workflow
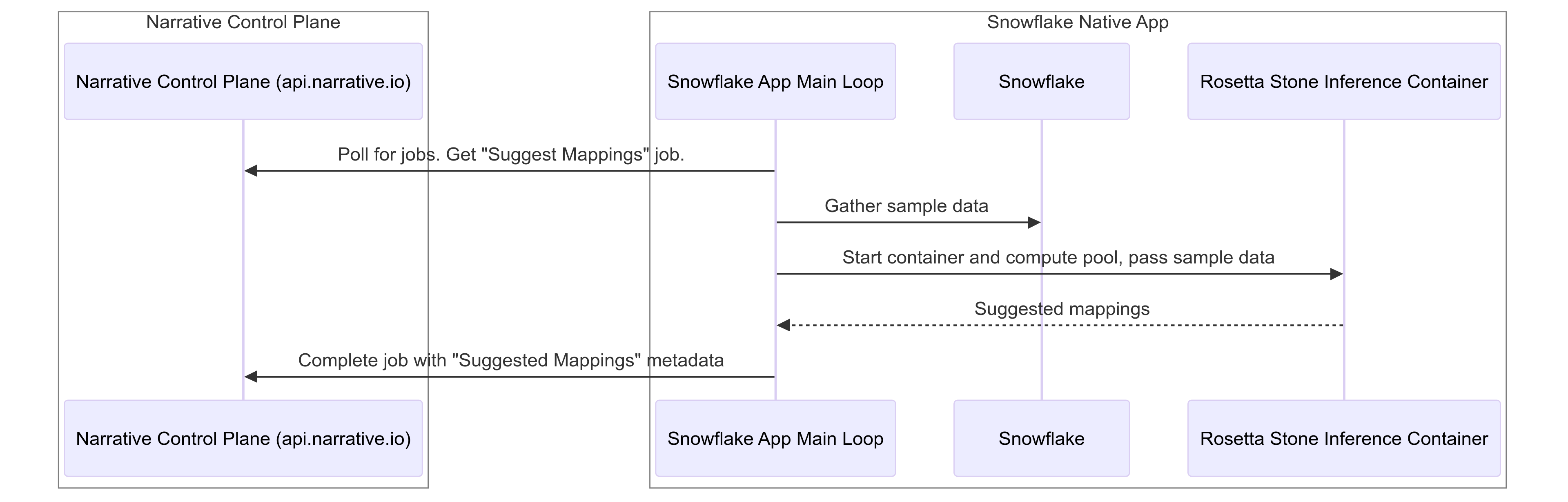
In this opt-in workflow, the Snowflake Native App integrates with Snowflake’s infrastructure and the Narrative Control Plane to generate mappings that help align a customer’s Snowflake tables with Narrative’s standardized data attributes. These mappings enhance data normalization and interoperability across the Narrative platform, supporting scalable and compliant data integration.
The following steps outline the data flow:
- Polling for Jobs (Narrative Control Plane):* The CommandExecutor in the Snowflake Native App checks the Narrative Control Plane for available jobs. When a "Suggest Mappings" job is found, it initiates the workflow to gather and process data.
- Gathering Sample Data (Snowflake API):* The CommandExecutor retrieves sample data from specific tables in the customer’s Snowflake instance using the Snowflake API. This sample data is constrained to selected rows and columns and is used only for generating mapping suggestions.
- Invoking Rosetta Stone for Mapping Inference:* With sample data available, the CommandExecutor initiates the Rosetta Stone Inference Container via Snowpark Container Services. This AI-driven mapping tool runs within the customer’s Snowflake environment, maintaining security by keeping all processing local to the customer’s infrastructure.
- Generating Suggested Mappings:* The Rosetta Stone container analyzes the sample data to produce suggested mappings. These mappings align the customer’s data fields with Narrative’s standardized attributes, supporting cross-platform data consistency.
- Returning Suggested Mappings to Control Plane:* The CommandExecutor then uploads the mapping metadata to the Narrative Control Plane. These mappings are stored and accessible for future data integration tasks, streamlining interoperability within the Narrative platform.